The challenge
In England and Wales, coroners issue Prevention of Future Deaths (PFD) reports when they believe action could prevent similar deaths. Since 2013, over 6,000 of these reports have been published — each containing detailed accounts of what went wrong and what should change. But the insights they hold are locked inside unstructured, inconsistently formatted documents. Manual review doesn't scale: formats vary wildly, metadata is frequently missing, and a single thematic study can take months (or even years) of researcher time. Patterns that could save lives go undetected.
What we built
We developed the PFD Toolkit — a fully automated pipeline that transforms raw coroner report text into clean, structured, research-ready datasets. The system scrapes reports from the judiciary website, uses optical character recognition to handle scanned documents, and applies large language models to extract structured fields: deceased demographics, death settings, coroner areas, categories, specific concerns raised, and recommended actions.

Validating with clinicians
Getting machines to read legal documents is one thing — trusting the output is another. We validated our automated extraction against a panel of clinicians who independently reviewed a stratified sample of reports. The system achieved agreement with clinical judgement in 97% of cases. This wasn't a lab exercise: the validation used real reports with all their messiness and ambiguity. Crucially, the toolkit surfaces the specific spans of text from each raw report that informed its decisions, so users can audit and verify every extraction rather than treating the system as a black box.
Speed and scale
What previously required months of manual review now runs end-to-end in minutes. In our replication of a major Office for National Statistics (ONS) study on child suicide reports, the automated pipeline identified 72 relevant PFD reports — nearly double the 37 found through the original manual process. The system processed thousands of reports published between 2013 and 2023, extracting structured variables and coding them against 23 concern sub-themes.
Designed for researchers, not just engineers
The toolkit is published both as a web app, and as an open-source Python package. Researchers can load reports with a few lines of code, screen cases against specific criteria, discover themes, and produce categorised datasets — all without needing to understand the underlying language model infrastructure. Every extracted insight links back to its source report, so nothing is a black box.
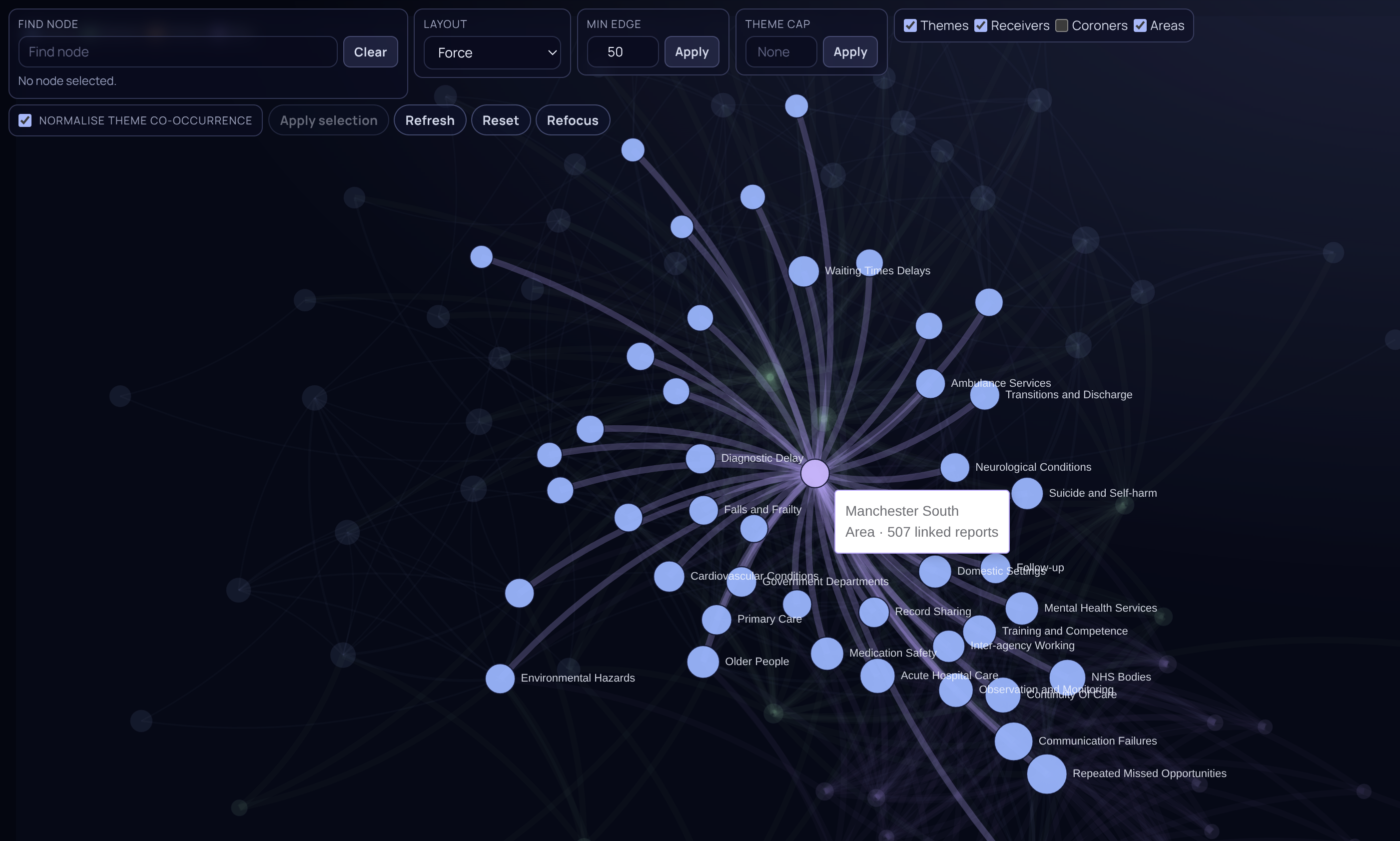
The outcome
The structured dataset enables trend analysis across time, region, and cause of death, giving public health teams the evidence base they need to advocate for targeted interventions. The approach offers a transferable framework for large-scale analysis of other complex, unstructured records in healthcare, legal, and regulatory contexts.